The heart is a vital biological pump, beating around a billion times in a lifetime. But faulty genes can cause big problems. Plus, taming the tiger genome, solving citrus sickness, and our gene of the month is for all you hopeless romantics out there.
In this episode

01:01 - Prof Aroon Hingorani - Heart risk genes
Prof Aroon Hingorani - Heart risk genes
with Professor Aroon Hingorani, UCL
Kat - A heartbeat is the sound of life itself, and our hearts beat thousands of times a day, pumping blood around the body. But things can go wrong. Cardiovascular diseases - such as heart attacks and strokes - are responsible for around one in four deaths here in the UK, and someone in the country dies of a heart attack every seven minutes. As you might expect, genes play a role in our individual risk of heart problems, so I spoke to Professor Aroon Hingorani, director of the UCL Institute of Cardiovascular Science to find out what we know so far about the genetics of heart disease.
Aroon - There's been an increase in our understanding of a lot of genes in cardiovascular disease over the last decade or so. So, it's long been known that heart disease tends to run in families. There are few rare conditions that are caused by single genes. They tend to be quite rare, but the genetic effects tend to be quite large. Most of the common cardiovascular diseases in late life also have a genetic contribution. The model has been that probably, the risk is increased by small effects of a very large number of genes and the challenge has been to try and identify those genes.
Kat - So, if you have a lot of these kind of bad variations, you're much more likely to get heart disease or a related condition. And if you only have a few, your risk is lower.
Aroon - Exactly right. So, the challenge has been to try and identify which are the points in the genome where these variants lie that influence disease susceptibility. So, over the last 10 years or so, there's been an increase in our understanding of this, through what are called genome-wide association studies. Typically, what these do is that they compare the frequency of these common variants in the genome between people who have the disease and people who don't. And where there's a difference in frequency variance in the disease cases versus the control, that highlights a point in the genome that contain genes that includes disease risk. So, for coronary heart disease for example, we know that there are about 46 or so regions of the genome that imprints all risk of suffering a heart attack.
Kat - We hear all the time that there are things about diet and exercise, and salt, and all these things we can do to reduce that risk of cardiovascular disease. What proportion is the influence that's in our genomes?
Aroon - It's clearly immensely important that dietary and lifestyle factors are corrected to reduce the risk of cardiovascular disease. So, the things that are particularly important are diets high in saturated fat and high salt, which influence cholesterol and blood pressure which are known to be causal factors in heart disease. The genetics and the environmental factors act in an interplay, so I don't think we can divorce from the other. Clearly, you can modify your environment; you can't modify your genome. What the genetic studies do is they highlight those pathways and those environmental exposures that are causally related to disease. So, they can actually give insight into the sorts of things that we should be modifying or treating with drugs to reduce disease risk.
Kat - Where have we got to in terms of translating the things that we've discovered from these big studies into the clinic? How close are we to that?
Aroon - So, there's probably two main areas where people are trying to utilise genetic information to improve personal and public health. One is to try and use the information to try and better predict who's going to get a cardiovascular event in later life. The other is to use the information to understand the mechanisms of heart disease a little bit better. One problem with the first translational opportunity, the use of genetic variants to try and improve prediction of future disease risk, is that the effects of each variant tends to be quite small. Now of course, there are people in the population who carry a larger number of risk variants who are at higher risk of disease. But they tend to be relatively small in number. Most of us carry an intermediate number of risk variants that influence our risk of disease.
A particularly exciting area though is the use of the genetic information to understand the mechanisms by which disease risk is increased because through understanding the mechanism, it should become possible to develop new therapies to treat or prevent heart disease risk.
Kat - So, how can you do that? How can you mine all these genetic data to find new targets?
Aroon - That's a really interesting question and it's an area that we're actively pursuing. Let me illustrate this with an example. There are drugs called statins that are widely used in the treatment and prevention of cardiac disease. They work by lowering LDL cholesterol, a risk factor for heart disease. So, it turns out that when the genome-wide association studies were done, one of the genes that came up being associated with an increase risk of disease was the gene that encodes the protein which is the target of statin drugs. It's called HMG-CoA reductase. So, one can do a sort of thought experiment and ask the question that if the drug haven't been invented, but the genetic information was known, that would've motivated the development of the drug at that time.
Kat - So, you were looking for people who naturally have lower levels of this and if they have a low risk of heart disease, you can go, "Oh well, maybe lowering that protein would work."
Aroon - Correct. So, targeting that protein might be a good way of preventing heart disease in people who don't carry that variant. So, we've been working ,and others have as well, in trying to mine the genetic information from genome-wide association studies and try and utilise it, to try and identify those pathways in proteins that might be most amenable to targeting with new treatments to reduce heart disease risk.
Kat - What do you think are the most promising targets so far? What have you found in this data trove?
Aroon - So, that's very much work in progress, but what I can say is that there are some exciting opportunities that we think will arise from this sort of activity. I guess the challenge over the next five to 10 years is to capture that information, prioritise it because it's a lot of data there - it's a big data problem - and to try and identify those proteins in pathways where the translational opportunity is foremost, once that we could try and capture early on.
Kat - Where have we come in recent decades in making an impact in improving outcomes in heart disease and where would you like to see us go over the next say, 10 to 20 years?
Aroon - So, it's interesting that the epidemiology of cardiovascular disease is changing globally. So, in high income countries, there's actually been a fall in cardiovascular mortality through better public health measures, better acute treatments, and better preventative treatments, and through reduction in smoking. So, public health measures have had a key role to play. But more people are living with the consequences of cardiovascular disease including heart failure and arrhythmias. Actually, we do need new therapies for those disorders because there's a substantial unmet need in those areas.
There's also a concern that in low and middle income countries, rates of cardiovascular disease are increasing and eventually, may outstrip infectious diseases. A particular concern is the epidemic of obesity and type 2 diabetes. Both of which are risk factors for cardiovascular disease. So, in high and middle income countries, we can say there's been some success, but there are new challenges, people living with the consequences of heart disease. And in low and middle income countries, there are increasing rates of heart disease which pose a challenge.
Kat - That was Professor Aroon Hingorani from UCL.

08:37 - Gene links across cancers
Gene links across cancers
with Nell Barrie
Nell - So, this first story is a really interesting one. It's called The Cancer Genome Atlas. The main part of it is the Pan-Cancer Initiative. It's all sounding very exciting already. Basically, what this is all about is probing the genetic faults of the heart of several different types of cancer. You might have noticed that The Cancer Genome Atlas - TCGA.
Kat - It's the letters of the DNA!
Nell - I didn't even notice because it was so nerdy, but now that I have, I'm really enjoying it a lot. The idea is that they're looking at all the different types of genetic mutations you get across many different types of cancer. We're finding patterns, so this is really a part of this move away from classifying a cancer based on where it starts in the body, moving to understanding exactly what mutations it has and starting to treat the cancer based on that, not based on where it started.
Kat - They've just published this first group of papers. That's about 18 papers published in Nature Genetics and other journals, really getting to grips with some of these massive, massive data sets to look for patterns. What kind of things have they found?
Nell - So, it's really interesting because I suppose the first thing which we sort of suspected would be the case, and it's certainly been coming out in more and more studies, is that different types of cancers, say, breast cancers and bowel cancers may sometimes actually have the same mutations. This is great in one sense because it means that you could maybe be re-using drugs that have only been used for one type of cancer, and starting to use them for another type of cancer. So, that's great in terms of speeding up development of new treatments. But the other thing that's come out of this which is kind of a bit more broad is that you can actually divide mutated cancers into these two groups. So, there's one type where the chromosomes are just completely messed up and in the other group, it tends to be all these small point mutations that are messing with specific genes. So, we're see some of pattern there, in how these mutations were actually occurring in the cancer cells.
Kat - They are really interesting results when you get to grips with them and fascinating things like, they found that some head and neck cancers were similar to about 10 per cent of bladder cancers. They share the same gene faults and that means you could potentially use the same treatments across those different types of cancer. There are big implications for treatment and also for clinical trials, I think.
Nell - Yeah, absolutely. So, instead of saying, "Okay, you've got bladder cancer. You're going to go on a bladder cancer trial", you would look straight away at the mutation and you can then really just build the trials around the types of mutations that you're trying to target rather than where the cancer started. And this could be really, really helpful because it might mean that you can pull out those small groups of patients who maybe don't benefit from current drugs and find something that is going to work for them and really start to pull out all that data from this interesting knowledge that we've got.
Kat - And I think there's another group that could benefit and that's patients who have a cancer called CUP or Cancer of Unknown Primary. How could they benefit?
Nell - Yeah, I think that would be really interesting for this because this is actually surprisingly common that somebody will be diagnosed with a cancer that's already spread, but the doctors can't find where it started. At the moment, this is a real problem because it means we can't decide how to treat those cancers. If instead, you can just go straight to picking out these individual mutations and saying, "Right. Well this drug is definitely going to work. This one definitely isn't." It could mean that it may no longer be so much of a problem that you can't identify the place where the cancer began. So, that could be really helpful. CUP is actually about 9,000 cases a year in the UK, so it's not an insignificant number.
Kat - I think it's going to be a very exciting couple of years ahead of us.
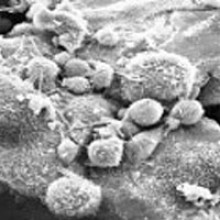
12:13 - Sister stem cell clues
Sister stem cell clues
with Nell Barrie
Kat - One of the other stories I noticed this month is from the Institute of Cancer Research, but it's not actually a cancer story. It's a really nice piece of work, looking at stem cells. What the researchers have done is incredibly fiddly - I can just imagine some poor PhD student or post doc's life being ruined by this! - but they've taken stem cells growing in the lab in a dish - embryonic stem cells - and they've watched as they divide. They've picked out the two new sister or daughter cells that have been created from one cell dividing, sucked each of them up separately, and analysed all the genes that are switched on in those cells. It's an incredible technical feat. What they found was really fascinating because you'd expect two daughter cells that have just come from one cell to be the same. Actually, they had wildly different patterns of gene activity and this is kind of weird, I think.
Nell - Yeah. It's certainly not what you'd expect especially when you're kind of picturing these two little cells, surely they're exactly the same, but it turns out that they're not and it's kind of almost the next level from the story we were just talking about. So, you're not looking at the mutations, you're looking at more subtle changes to how the DNA is expressed, how it's switched on. It's really interesting to see that there's actually quite a lot of difference between two cells like that.
Kat - And they're starting to get a handle on what's causing this difference because they treated the stem cells with a cocktail of chemicals which is called 2i. Apparently, this reverts the cells back to a more stem cell-like state. It does this by interfering with the process called DNA methylation. This is basically like putting kind of Post-It notes on the DNA saying, "Don't use these genes. Use these genes." When you mess up that, they actually found that the stem cells were a lot more similar and this is delving into the territory of epigenetics and showing that that's probably responsible for some of these differences.
Nell - Yeah. I mean, I think this is really interesting because when you sort of start to get into learning about DNA and you get all these stuff about you know, all our cells in the body have the same genetic code. You start to think, "Well, how come some of them do one thing and some of them do another thing?" And this is really getting to the heart of that and helping us to understand how one stem cell can give rise to all these different types of cell that go on to do amazingly specialised things. So, it has got some implications probably for some types of diseases, but really, this is just kind of understanding the whole process at the fundamental level.
Kat - I think it's absolutely fascinating and a real technical tour de force.

14:37 - Dwarf dog genes found
Dwarf dog genes found
with Nell Barrie
Kat - And finally, tiny dogs! I love this story. This is researchers in Finland who have been investigating dwarfism in dogs. What have they found?
Nell - So, this was looking at two both very cute breeds of dog, as I discovered after a Google search. One called the Norwegian elkhound which I think kind of looks like a really beefy Alsatian and one called a Karelian bear dog which looks like a beefy border collie.
Kat - They found faults in a gene called ITGA10. It actually causes the dogs to be dwarfs. They have shorter limbs than normal dogs. They have lots of skeletal abnormalities in these poor little dogs. But now, they've actually found this faulty gene. It turns out it also could be involved in human dwarfism syndromes that are similar. They're called chondrodysplasias. So, I think this has got quite a lot of potential, this finding.
Nell - It's really interesting. So, I guess it's coming down to how the bones are developing and something that's gone wrong in that process and really starting to understand how that can affect the body. I was just thinking it's really interesting that you can have a fault in just one gene that has such a big effect on an animal's physiology. So, yeah, it'll be interesting to see how that's going to affect human diseases, and apparently, they've already started looking at human patients to see if they might have similar mutations.
Kat - And as far as the dog world goes as well, once you can test for this mutation, you can actually start to breed it out of the populations. So, unfortunately no more cute dwarf dogs but hopefully, healthier dogs as well.

16:05 - Tiger genome tamed
Tiger genome tamed
Writing in the journal Nature Communications, scientists in South Korea - along with colleagues as far flung as Namibia, India and Mongolia - have analysed the genomes of a number of big cats, including the tiger, lion and snow leopard. The results reveal how the animals have evolved to be predatory killing machines that thrive on meaty diets. To date, the only cat to have had its genome analysed was the domestic moggy, which shares more than 95% of its genes with a tiger.
The researchers read DNA taken from animals living in zoos, creating a reference sequence that other big cats around the world can be compared against. The scientists hope that their work will support conservation efforts, allowing researchers to look at genetic diversity in big cat populations. Fewer than 4,000 tigers are thought to survive in the wild, so the new data could help zoos plan their breeding programmes to help maintain diversity.

16:53 - Citrus sickness solved
Citrus sickness solved
Scientists in the US have used genetic techniques to solve a murder mystery - in citrus trees. Trees in Florida have been suffering from a disease called citrus greening, or Huonglongbing, which causes severe damage to leaves and fruit, eventually killing the tree. And it seems to be spreading, threatening the US' multi-billion dollar citrus industry.
The disease is caused by bacteria, which are spread by little insects. But previous research had shown that the bacteria weren't carrying poisonous toxins, so how they caused the disease was a mystery. Using genetic technology, the scientists analysed the patterns of gene activity in infected and non-infected trees, and found that the bacteria caused changes that interfered with nutrient transport and production. They also interfere with the production of plant hormones, which are important for growth and fruiting. The team hopes that their findings will lead to better tests to pick up the disease at an earlier stage, so it can be prevented from spreading further. And there's hope that they might be able to develop some kind of treatment to help the trees that have already caught the bug.
 or two human microRNAs strongly increasing cardiomyocyte proliferation (middle and right).")
18:00 - Prof Hugh Watkins - Sudden heart death
Prof Hugh Watkins - Sudden heart death
with prof Hugh Watkins - Wellcome Trust Centre for Human Genetics
Kat - Premiership footballer Fabrice Muamba hit the headlines in 2012 when his heart stopped on the pitch for more than an hour. Incidents like this are usually due to inherited gene faults, which are often not known about until disaster strikes. British Heart Foundation Professor Hugh Watkins, at the Wellcome Trust Centre for Human Genetics in Oxford, is trying to track them down.
Hugh - So, I look at conditions that cause young people, mostly kids, teenagers, young adults, to be at risk of catastrophic changes in the function of the heart that just cause you to drop down dead. And so, the uncommon, they're not unheard of. You'll have seen them in the public eye. So, when this happens in the public form often in sports, it's a young sports player, it's usually one of these familial conditions that causes it.
Kat - And so, by understanding these genes, this is directly changing the way that you work with families to do this.
Hugh - Yeah, absolutely. So, in my clinic, I will use DNA testing on a routine daily basis and it completely transforms the way we do work. So, that's very exciting. Some of these conditions are not very easy to diagnose by clinical tests. And so, when you think someone's got one or you find they've definitely got one or sometimes it happens quite commonly as a tragedy, you only work out after they died what they had. The question then comes, "Who else is at risk in the family?" And because it's one gene that comes down to maybe your mum or your dad, by and large, each immediate family relative has a 50/50 chance of that condition.
And so, what we now know is that for most of these conditions and there are many different ones with long names, there's usually a bunch of genes that could do it. In each gene, there would just be one gene change. So, if we have a person who's definitely got the condition, we will do a fairly large genetic analysis for all the genes, looking for that single 'spelling mistake'. If we can find it and be confident we have found it - it isn't always easy - that's a really powerful tool for then saying, "Who in the family might be at risk or who is not?" And the beauty of it is, that if you don't have that gene change then you won't have the condition and you don't need to be followed up and nor your kids. So, it's a very powerful way when there's been one of these alerting cases, and sometimes a tragedy case, to then work out who else we need to worry about. And we've got quite good cardiology treatments for people if we can diagnose them with these conditions.
Kat - Because it's all very well to find genes and say, "You're at risk" but if there's nothing you can do to intervene, that's not helpful. So, this is great - there's something you can do.
Hugh - It is. I mean, if you had nothing to offer, you probably wouldn't want to do this work at all. You would want to tell somebody that they're at risk if you couldn't improve it. If we find an individual who's clearly a high risk, we can implant a device like a glorified pacemaker that sits there and monitors the heart. If the patient has one of these sudden chaotic life-threatening heart rhythms, the machine will charge up and give electric shock just like you can see in the patterns in television dramas like Casualty, and that's life-saving. But these are complex, scary, sometimes dangerous devices that you don't want to use if you don't need to.
So, in another part of the programme of work is ask the question, now we know what the genes are and we can define what proteins that the genes code for, you'd think that would give us a clue as to what the disease pathways are. And that's a big thrust of our work and it's gone quite a long way. We now have some quite tangible and testable ideas, and are beginning to do clinical trials with new treatments. They're looking very promising.
Kat - So, that's one aspect of your work, but another aspect is looking more broadly at heart disease-associated conditions to find the complex susceptibility genes. Where has that got to now?
Hugh - A better story now than it was a few years ago, We started this work as did many groups in universities around the world, probably 10, 12, maybe even 15 years ago, and it's proved to be much harder than we thought. The reason is, as you will know, is that there's not one gene for heart attack or one gene for diabetes. There aren't 5, 10 or 20. There are hundreds, potentially, thousands of genes or changes in genes that make people just very slightly more or less at risk. And so, it's only recently that we had powerful enough genetic tools and big enough clinical studies that we can begin to find genes. Actually, we are now doing analyses on tens of thousands of patients.
When you do that then you do find these genes. Our list at the moment in terms of what we've published is around 46 newly identified genes which makes you a bit more likely to get a heart attack. It's exciting because they're not by and large the obvious genes we would've guessed. Some of them are. Some of them are genes that regulate how you handle cholesterol in the body and it's reassuring that we could get those positive controls. Some of them, we thought we knew what the gene did or the protein that it codes for did, but wouldn't have guessed it was involved in coronary disease or heart attack.
So, that's quite surprising. The fair number, we have no idea what they do. And so, that's good and bad. The good news is, there's a lot of opportunity for new biology. If we can understand new pathways that cause you to have a heart attack, there's lots of scope there for new drugs and medicines to stop it.
Kat - And there is this sort of idea that you'll be able to have a genome scan and will know your risk and you do this and take this drug, and do that, and you'll never get a heart disease.
Hugh - Yes, it's quite a nice dream, but it's a bit of a pipe dream. If you unpack all the sort of two or three components of the aspiration, one was that you could do the genome scan and predicting individual's risk. That's not looking very effective at the moment. So, most of us are fairly average in our genetic risks. If you take someone in a clinic and look at their hundreds of genes that contribute to their risk, they're not very likely to be very high or very low. If you do the whole population and find people that were high and low and that might work. But for an individual, it doesn't work so well.
And then the other thing is we've already got pretty good tools. They're not perfect but very powerful affects - age, gender, smoking, cholesterol, blood pressure, diabetes - are really quite strong predictors of heart risk. It's quite a high ask for genetics to make that better. So, at the moment, I don't think we look at this complex genetics as a tool for prediction. But rather, it's a tool for maybe classifying people into broad groups, but particularly, for trying to come up with new targets and new treatments. So, I'm very optimistic it will work, but actually, it will take time.
Kat - That was Professor Hugh Watkins, from the Wellcome Trust Centre for Human Genetics.

Is there a role for DNA ends?
Kat - Now it's time to look at your genetics questions. Richard Thornley asks "What is the very first and last piece of DNA on the chain responsible for? Is it a marker, or solely to indicate the ends?" To answer, here's Dr Jessica Greenwood from the Telomere Biology lab at the Cancer Research UK London Research Institute.
Jessica - I really like this question because it highlights the fact that the ends of the DNA called telomeres actually have a number of important responsibilities. One of which is to indicate the end. So first, what is a telomere? A telomere is a structure found at the end of the DNA in all organisms with linear chromosomes. In most organisms, the underlying foundation for the telomere is the DNA sequence, which is a unique stretch of short repeats. This DNA does not contain genes that code for protein, but it does create a unique region in the DNA upon which telomere-specific proteins bind and form the telomere.
It's the very fact that the cell knows that the telomere is the end that protects the end itself and therefore, the entire genome. You see, the cell is always on the lookout for breaks in the DNA chain and when the break is discovered, the cell acts quickly to repair it by sealing broken ends back together. If it weren't for the telomeres, indicating to the cell that the end was an end, the cell might be under the mistaken impression that the end was in fact a break. And then this would be extremely dangerous because if the cell attempted to repair the end, it could seal it to another chromosome end and the chromosomes would get stuck to each other in this manner. It would lead to serious problems when the cell try to divide and separate this DNA into daughter cells. So, end protection or capping as it's known is an absolutely critical role for the telomere.
But there's another equally important job for the telomere and that is to help guide the enzyme that adds the unique DNA sequence to the ends, called telomerase. Because your cells are constantly making more of themselves, they prepare for this by copying their DNA and then dividing it so that one copy ends up in each daughter cell. The copying of the DNA is not completely perfect. At each time a copy is made, a little bit on the end is missed. While this may sound like a bad thing, it's actually another built-in safety device to impose a life span on our cells because we don't want our cells to just be able to divide without end.
So, most of our healthy cells actually have turned off telomerase because we don't want them to be able to keep dividing. Cancer cells have found a way to re-activate telomerase. This unfortunately allows the cells to continue to make copies of itself. So, you can see that actually, the end, the telomere does have and number of important roles in protecting the cell, both in survival and making sure that it doesn't get out of control.
Kat - Thanks to Dr Jessica Greenwood, from the Cancer Research UK Telomere Biology lab. And if you've got any questions about genes, DNA and genetics you'd like us to answer, just email them to me at genetics@thenakedscientists.com.

28:13 - Gene of the month - Lonely Heart
Gene of the month - Lonely Heart
with Kat Arney
And finally, our gene of the month is one for all your romantics out there - it's Lonely Heart. Only discovered this year, Lonely Heart is a fruit fly gene that's involved, as you might have guessed, in building their tiny hearts. Loss of the gene leads to heart damage and eventually, in the words of the scientific paper describing it, "abolishment of heart function".
Lonely Heart carries the instructions to make a protein that helps to make a kind of molecular glue that holds together the muscle of the fly's heart and the sheath that surrounds it. When this glue breaks down, the heartbeat becomes irregular and everything starts to go wrong. There are other proteins related to Lonely Heart out there, but it's not clear exactly what they do. Perhaps they're also involved in creating molecular glue too?
- Previous Tunnelling Under London
- Next Why pulling nose hairs makes you cry?










Comments
Add a comment